1. Background (video)
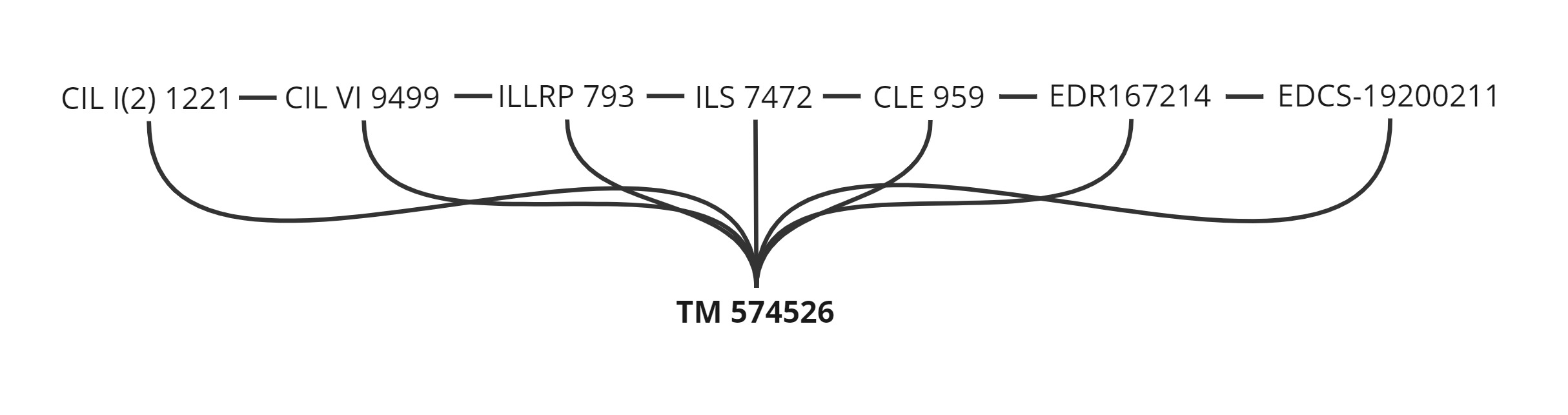
A reference of the type "CIL I2 1221 = CIL VI 9499 = ILS 7472 = CLE 959 = ILLRP 793" is probably familiar to those who use epigraphic sources. In giving such a reference, what we are doing, formally, is saying that these different editions all describe the same original physical epigraphic text (these editions may in fact be slightly different, a point which the "=" symbol obscures, but they are all different interpretations of the same text). The reason we tend to give references in this form is because there are often multiple editions, and there is no one corpus where all the inscriptions are presented and to which all epigraphers can reasonably be assumed to have access (the original corpora projects which tried to achieve this, CIL and IG, are now often neither the most recent nor the most accessible editions). This situation is now further complicated by the creation of digital datasets of inscriptions, which each assign their own identifier, even when they reproduce an existing edition (so the above reference could, for example, be extended as "= EDR167214 = EDCS-19200211"). In the world of linked data in particular, what is missing in this situation is a single unique identifier, which serves to disambiguate such multiple references, and represents the individual inscription in the abstract, rather than through a particular edition. Such an identifier is now provided by the Trismegistos number, which in turn makes it theoretically possible to connect up all existing identifiers.
Epigraphers can obtain Trismegistos Identifiers and other digital corpora identifiers from the Trismegistos TexRelations MatcherAPI by providing the different source identifiers. This process takes time because epigraphers need to fetch TM IDs by providing them one-by-one from different source IDs; but it is also a non-trivial task for most epigraphers to query the API directly. The Inscriptiones Identifier Resolver (IDR) helps the epigrapher to fetch the ids in a more efficient, user friendly and less time-consuming way.
The Inscriptiones Identifier Resolver (IDR) is designed as a tool to fetch
Trismegistos Identifiers (TM ID) using the TexRelations Matcher API by
providing other epigraphic identifiers and vice versa. For instance, the user uploads a input file
(CSV) with inscription IDs from a project partnered with Trismegistos, and IDR returns an output
file (CSV) with the IDs from other partner projects as requested by the user, along with the
original IDs. A simple web-based user interface makes this a more user-friendly task.
As the TexRelations API of Trismegistos is a dynamic tool and new connections are added over time and some are changed - and this interface may not keep pace with those changes - we encourage those who want to add live links to other projects to their websites to establish a direct query of the API (for which they can also contact the TM team). Also, TM would strongly appreciate it if you acknowledge the use of the API where appropriate, including when you access it through this interface.
2. Approach
We make this possible using the following technologies:
- Trismegistos TexRelations MatcherAPI
- JavaScript for the back-end
- HTML/CSS for the front-end (GUI)
3. Methods (demonstration video)
IDR has two main interfaces: a single identifier resolver and a multiple identifier resolver.
3.1 Single Identifier Resolver
Example scenario: I have a single ID from I.Sicily and I want to get the corresponding TM ID and all other corresponding IDs of the same inscription in other projects.
In this method, the user selects the data source for the known ID and provides the relevant single ID with which to fetch the other IDs, including the TM ID (discussed in detail in section 4).
3.2 Multiple Identifiers Resolver
Example scenario A: I have a CSV file with combination of multiple I.Sicily IDs and EDR IDs and I want to get all corresponding TM IDs.
Example scenario B: I have a CSV file with multiple I.Sicily IDs and TM IDs and want to get all corresponding IDs in other projects (e.g. EDH and Ubit Erat Lupa).
In this method, the user provides a CSV file that includes the known identifiers as input in order to fetch the corresponding TM IDs; or the user provides TM IDs as input in order to obtain other corresponding data source IDs.
-
Input File format (CSV)
The input file must be in the required format. The required format is as follows:
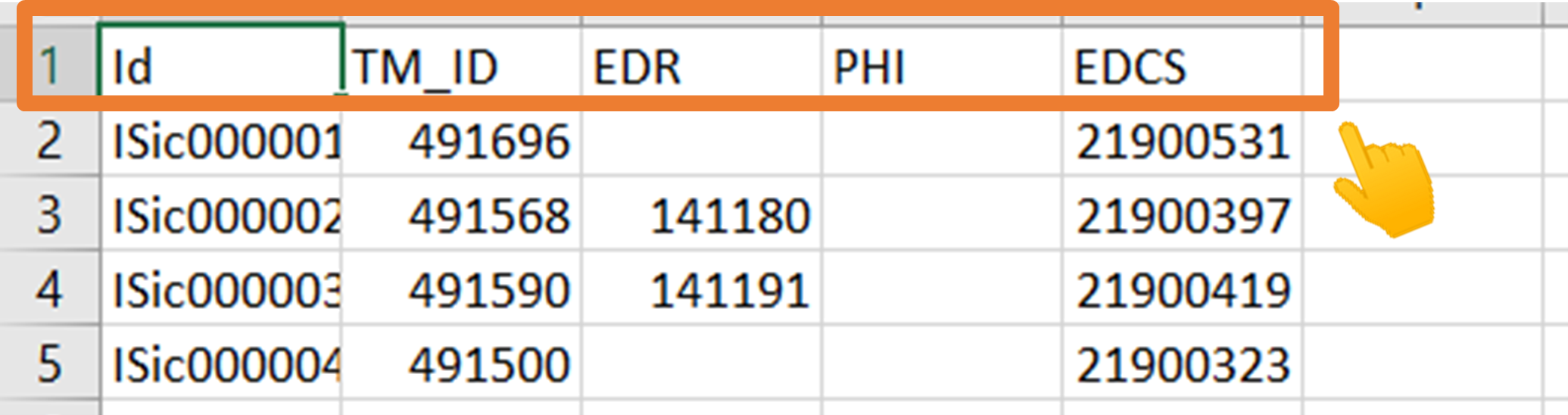
In the above figure, the column headers of the CSV file are highlighted in orange. The first column is optional, but if included should contain unique identifiers for your data source (to enable easy reintegration with your own dataset). In this example, we have used I.Sicily data as the source ID, with the heading 'Id', but this could be any unique identifier of your choice. Other column headers must be in the JSON_Key format required by the
Trismegistos Matcher APIdata sources (see figure below for a list). The values in each column must be formatted as a number, without any prefix. For testing you can use our sample CSV I.Sicily example.
4. GUI (Graphical User Interface)
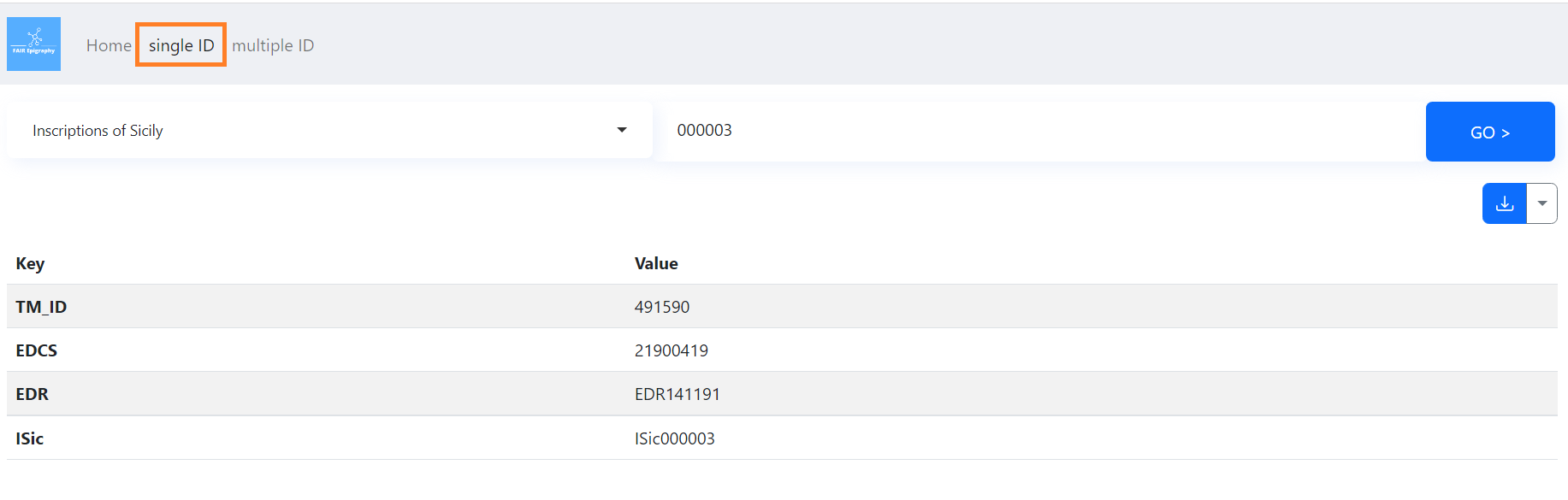
This tool has three pages (Home, single ID and multiple ID). The Home page provides a project overview. The Single ID Resolver page is the interface for fetching the different IDs corresponding to the provided ID.

To use the Single ID Resolver, select the source of your input ID from the dropdown menu on the left;
enter the ID number (only, without prefix) in the field on the right; and select ‘Go’. You can test
what happens if you select ‘Inscriptions of Sicily’ on the left and input 000003 on the
right.
Multiple ID Resolver
The Multiple ID resolver page returns multiple IDs in response to an input CSV file. Use
the Browse button to select and upload your CSV file.
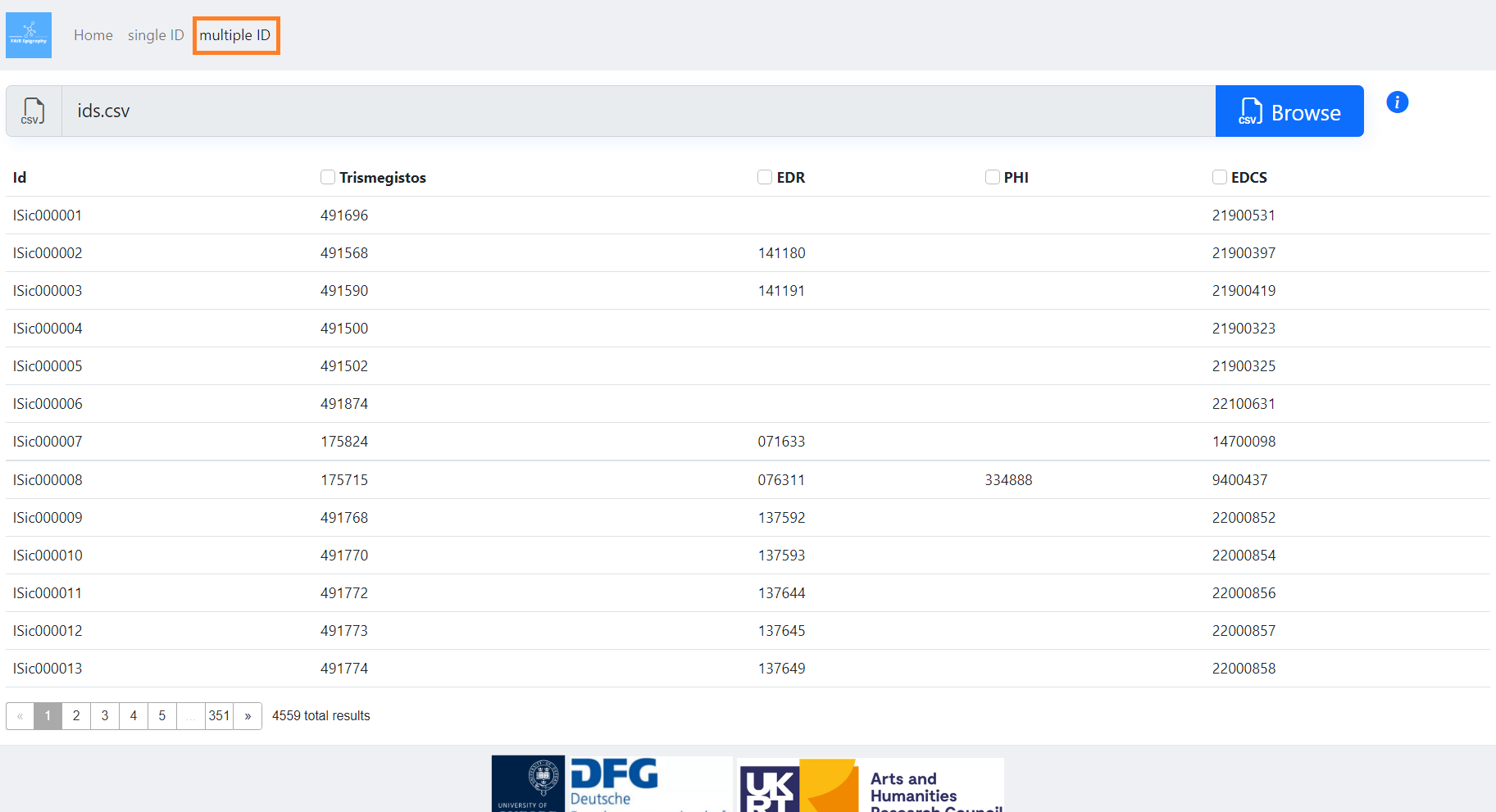
The CSV file has to be properly formatted as described above in 3.2. For testing you can use our sample CSV I.Sicily example.
The user selects the input column(s) from the CSV file that s/he wants to use to fetch other
corresponding IDs. Once one or more columns have been selected as input, the Fetch
button will appear on the page.

When clicking the Fetch button, the user will be presented with another menu listing
all the available data sources. The user selects the required data source(s) that s/he wishes to be
searched for corresponding IDs and downloaded. TM IDs will be downloaded by default.
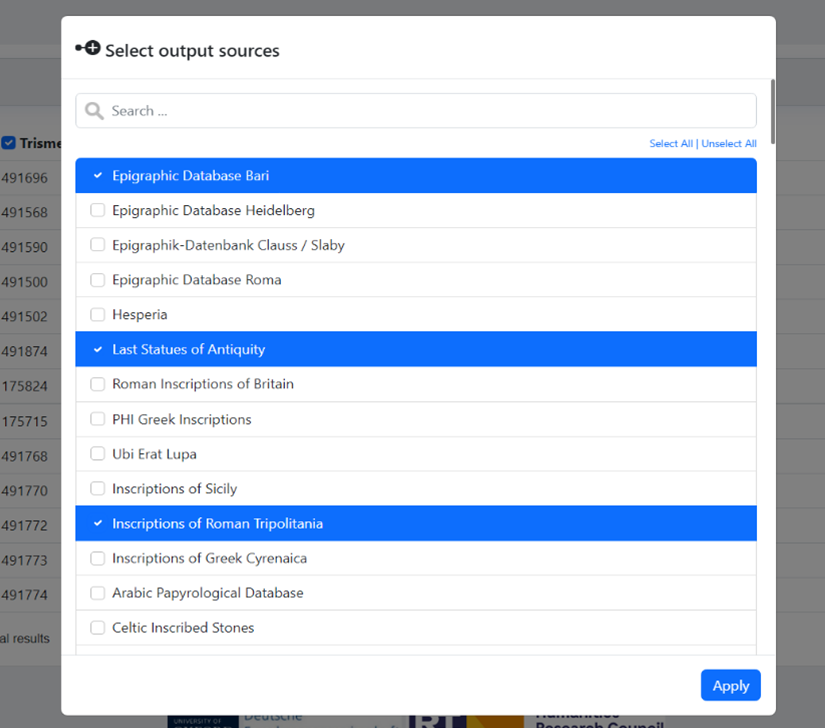
After clicking on the Apply button, the Resolver will fetch the data from the
Trismegistos Matcher API; progress is reported on the pop-up screen and can be paused /
interrupted (and results to date downloaded) at any time.
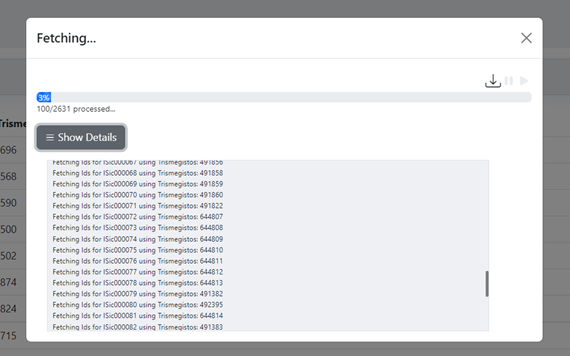
After completing the process, the user can download the file in a CSV format to their local computer.
5. Limitation
The following datasources do not appear currently to be implemented in the TM API.
6. Contributors
7. Acknowledgements
The Inscriptiones Identifier Resolver makes use of the Trismegistos TexRelations Matcher API and the TM data available under a CC-BY-SA 4.0 licence.
For more on the Trismegistos project, see:
M. Depauw / T. Gheldof, 'Trismegistos. An interdisciplinary Platform for Ancient World Texts and Related Information', in: Ł. Bolikowski, V. Casarosa, P. Goodale, N. Houssos, P. Manghi, J. Schirrwagen (edd.), Theory and Practice of Digital Libraries - TPDL 2013 Selected Workshops (Communications in Computer and Information Science 416), Cham: Springer 2014, pp. 40–52. [online copy]